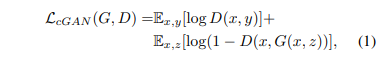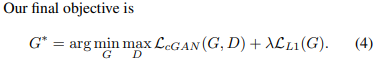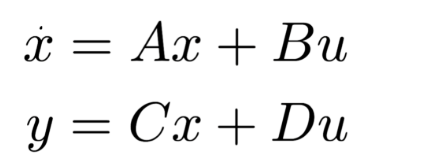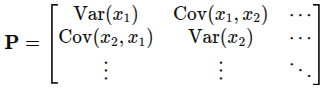참고 : https://darkpgmr.tistory.com/82
오늘은 PnP 에 대해 알아보겠습니다.
PnP : Perspective-n-Point 란
2차원에서의 점들과 이에 대응되는 3차원의 점 n개가 주어진 경우에
카메라의 pose R,t를 구하는 문제를 말합니다.

실제 우리가 카메라의 외부 파라미터 ( pose ) 추정을 한다고 생각하며 예시를 들어보겠습니다.
우리는 이미 알고 있는 object에 대한 사진을 찍었고, 해당 사진을 찍었을 때 카메라의 pose [R |t] 를 구하려고 합니다.
object의 국소적 특징 모서리, edge등을 통해 이미지(사진)에 찍힌 2D상의 점과
대응되는 3D point cloud상의 모델의 점(실제 3차원 현실에서의 점)에서 2D-3D 대응점들을 찾을 수 있었습니다.
해당 대응점이 3개 이상 존재하면 PnP알고리즘으로 카메라의 pose를 구할 수 있고,
이 pose는 object 좌표계 -> camera 좌표계 사이의 변환행렬을 의미하며,
반대로 생각하면 카메라 좌표계에서 object 좌표계의 변환행렬을 알 수 있음을 말합니다.
다시 생각해보면 물체의 pose 추정을 풀 수 있는 방법과 같음을 알 수 있습니다.
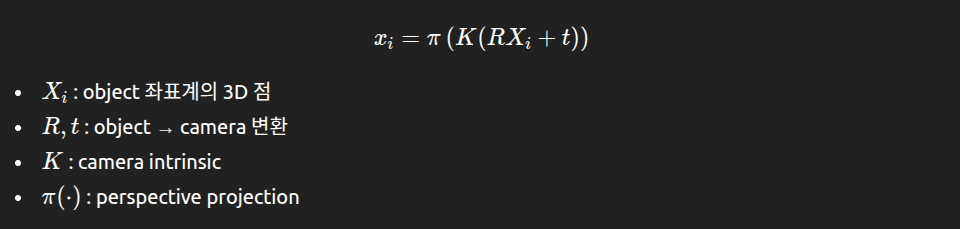
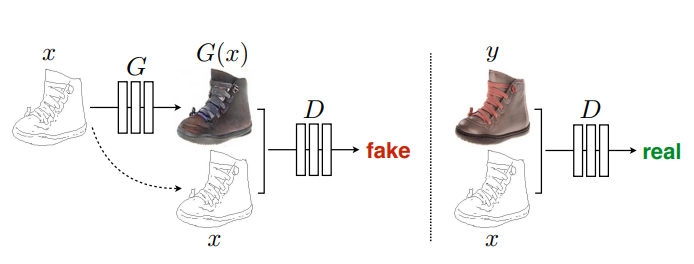
Xi는 object 좌표계에서의 3D 점, RXi+t는 카메라 좌표계에서의 3D점 입니다. pi를 통해 xi 즉 2D image 상의 한 점으로 mapping됨을 알 수 있습니다. 이 3개 변환 간의 관계를 잘 이해해야 해당 문제에 대해서 이해할 수 있습니다.
결국 우리가 풀고자하는 문제는 xi 와 Xi를 알고 있을 때, 이 사이에 있는 변환행렬 , 카메라 외부 파라미터 R,t를 추정하는 것입니다.
그러나 perspetive projection으로 인해, 해당 문제는 비선형 방정식을 푸는 문제로 변하고 풀기가 매우 복잡해집니다.
3차원에서 한 점은 Xi = (X, Y, Z) 의 성분을 가집니다. 그러나 2D 이미지 좌표는 xi = (u,v) 2개의 성분을 가집니다.
이러한 u,v와 X,Y,Z간 관계는 아래와 같습니다.

정규화 이미지 평면이 무엇인지, 왜 Z는 나눗셈으로 들어가는지 헷갈릴 수 있는데
보통 카메라 모델에서 좌표계는 총 3개로 표현되며
- 카메라 좌표계 (Camera frame)
- 정규 이미지 좌표계 (Normalized image plane)
- 픽셀 좌표계 (Image / pixel frame) 로 구분할 수 있습니다. 1. 은 카메라를 원점으로한 3D 좌표계이고, 2,3은 이미지상의 2D 좌표계입니다.

여기서 정규 이미지 좌표계란, 카메라 좌표계에서 위치한 3D 공간상의 점에서 카메라 좌표계의 원점으로 직선을 긋습니다.
여기서 z = 1의 거리에 2D 이미지 평면이 존재한다고 생각하고
해당 평면과 직선이 만나는 점을 정규 좌표계에 3차원 상의 P를 투영한 점 P'으로 정의합니다.


따라서 이러한 원리로 직선과 평면의 교점을 정규 이미지 좌표계 projection이라고 하는 것입니다.
이는 카메라가 보는 2D 좌표를 깊이(Z)의 영향을 제거한 순수한 방향 정보로 표현한 것입니다.
또한, 이는 우리가 최종적으로 만나게 되는 픽셀 좌표계에서 카메라 내부 파라미터 영향을 제거하고, 순수하게 기하적인 의미만을 가지는 좌표이기도 합니다.
- EPnP
EPnP는 존재하는 모든 대응점들을 사용해 R,t를 구하는 것이 아니라, 대표되는 4개의 대응점을 사용해 R,t를 구하는 방식입니다.
이는 3차원 공간에서 1개의 점은 4개의 대응점으로 항상 표현이 가능하다는 사실에 기반합니다.
추가적으로 3차원 공간에서 점2개면 직선, 점 3개면 평면을 표현할수 있듯이, 4개의 점이면 3D 공간 전체를 표현할 수 있다는 것입니다.
공간으로 설명하면 어려우니, 예시를 들어봅니다. 임의의 삼각형이 있고, 삼각형 안의 임의의 점 A가 있습니다.
A는 삼각형의 세변 기준점 a,b,c로 항상 표현될 수 있습니다 . ex ) 0.2a + 0.2b + 0.1c ... a,b,c는 벡터라고 생각하면 편합니다..
이러한 A의 a,b,c로의 비율은 삼각형이 회전/이동하여도 불변합니다.
이와 동일한 맥락으로 3D공간에서의 한개 object의 모든 점도 4개의 점의 결합으로 표현할 수 있습니다.
고정된 카메라에 대해 물체가 이동한다고 가정합시다.
이 경우에도 삼각형의 경우와 동일하게 한 개 object의 4개 기준점의 결합 비율은 불변합니다.
이제 카메라의 입장으로 가봅시다.

위와 같이 , 물체 좌표계에서와 같이 카메라 좌표계에서도 동일하게 한 점은 , 기준점 4개의 가중합임을 확인할 수 있습니다.
해당 식을 사용해서 기존에 풀고자 했던 R,t 추정을 단순화합니다.
원래 우리는 실제 3D 점 X가 2D기존에는 R,t 각각 6,3개의 자유도를 가진 방정식을 풀어야 했는데 반편에
'robotics' 카테고리의 다른 글
| EKF (0) | 2026.01.28 |
|---|---|
| EKF - Kalman filter (0) | 2026.01.27 |
| EKF_ 사전지식 ( covariance matrix , Jacobian , Gaussian ) (1) | 2026.01.27 |