오늘은 img2img 모델인 pix2pix gan 모델 논문에 대해 리뷰해보겠습니다.
https://arxiv.org/abs/1611.07004
Image-to-Image Translation with Conditional Adversarial Networks
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This mak
arxiv.org

1. introduction
- 해당 논문은 외국어를 translating ( 번역 ) 하는 것처럼 RGB 이미지를 image-to-image translation하는 task를 범용적으로 다룰 수 있는 framework를 제안한다.
- CNN과 같은 모델은 이미지 prediction에서 높은 성능을 보이지만, 이를 위해서 학습의 objective 즉 loss를 일일이 task에 맞춰 디자인하는 노력이 필요하다.
- 따라서 GANs을 사용하여, data에 adaptive한 gan loss로, 원래라면 여러 다른 종류의 loss가 필요했을 task들을 loss 디자인의 노력 필요없이 GAN하나로 가능하게 하면서,
이미지가 fake 처럼 보이지 않도록 함(D)과 동시에 loss를 최소화하는 방향(G)으로 이미지를 생성해낸다.
--
이미지를 내가 원하는 형태의 또 다른 이미지로 변환하는 img2img translation task를 범용적으로 다룰 수 있는 모델이 필요한데,
CNN과 같은 모델은 loss를 최소화하며 학습하는 과정은 자동이지만, 이 목적성인 loss를 디자인하는 것 자체가 어렵다는 문제가 있다.
특정 스타일이나 , 원하는 결과물에 맞추어 특수한 loss를 만들어 줘야 하고,
모델의 성능을 좋게 하기 위해 이러한 loss를 하나하나 디자인한다는 것은
결국 img2img translation이라는 task를 범용적으로 CNN이 할 수 없다는 말이다.
만약 단순하게 Euclidean distance로 loss를 설계하면, 이미지의 생성 결과가 모델이 그럴듯한 출력의 모든 것을 평균화하여 loss를 최소화해버리는 선택을 해버려 흐려 보이는 이미지가 결론적으로 나타난다는 점에서 저자는 각각 task에 맞춘 loss 디자인이 필요성을 말한다.
이를 해결하기 위해 저자는 GAN을 사용해 img2img를 하면
GAN은 loss가 data에 맞게 변화하는 특징을 가지고 있어 task에 loss가 맞춰서 학습을 진행하여
img2img라는 task를 범용적이게 할 수 있다고 하는 것이다.
2. Related works
1 . Structured losses
img2img 문제는 픽셀 단위의 회귀로 생각할 수 있지만, 픽셀 단위로만 생각하면 전체 구조적인 특성을 읽어버려 실제로는 이상하게 보이는 이미지를 생성해낼 수 있다.
2. Conditional GANs
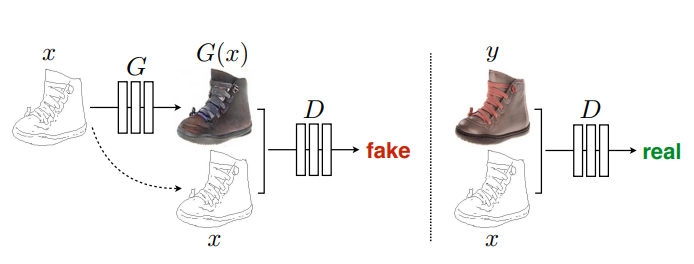
해당 논문에서는 condition 즉 , input img x이 들어가는 gan을 사용한다.
이게 무슨 말이냐 하면, 원래 본디 GAN의 초기 개념은 G 가 랜덤한 노이즈 z로 부터 점차 진짜같은 이미지를 생성해나가고, D가
이의 진위 판별을 하므로써 점차 두 모델의 성능이 좋아지는 것인데,
우리가 하고자 하는 img2img를 하기 위해서는 input x를 무언가로 변형해 output을 만들어내야 하기에
conditional Gan 즉 input ( condition )이 있는 gan을 쓴다. 아래의 그림을 보면 손쉽게 이해가 가능하다.
3. Method
method는 크게 1. loss 2. U-net generator 3. Patch GAN discriminator로 나눌 수 있다.
1. loss
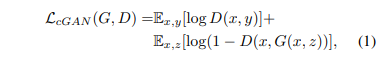
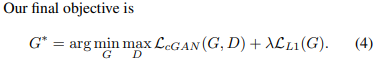
첫번째로 loss를 이해하기 위해 G와 D의 input output을 정확히 이해해야한다.
먼저 D는 discriminator로써, 두 개의 input (입력 이미지 x, 추론이미지) 가 들어왓을 때
추론해야하는 이미지가 실제 이미지(B)인지, G가 생성해낸 fake인지 구분해야 한다. (fake B)
이에 대한 추론 결과가 0~1 사이의 확률로 나오며, 추론이미지가 진짜라고 판단하면 1에 가까운 확률을 return한다.
두번째로, G는 입력 x(condition)과 ramdom한 noise z를 바탕으로 가짜 이미지를 생성해낸다. (fake B) 이게 return값 그 자체다.
이를 바탕으로 위의 (1)식을 봐보자.
D를 우선적으로 보면 앞의 항은 진짜를 D가 판별하는 상황이므로 더 커져야 D의 성능에 좋다, 뒤의 항은 가짜를 D가 판별하는 상황이라서 D의 return값이 작이지면 좋은데 1- []이므로 뒤 항도 커져야 D 성능이 좋은 것이다.
즉 , D입장에서는 전체 식이 커져야 성능에 좋은 것이고,
반대로 G입장에서는 D를 속여야 즉 뒤의 항의 값이 작아져야 G가 잘 하는 것이기에 전체 항이 작아져야 한다.
이러한 내용이 아래 (4)식에 minmax로 나와있다.
눈치챘을 수 있지만, 해당 loss는 G , D에 대해 동시에 계산, 업데이트가 쉽지 않다. 어느 한쪽은 고정되어 있어야 계산이 편리하기에 실제 학습에서도 순차적으로 backward를 진행한다.
여기서 기댓값으로 감싸져 있는 것은 실제로는 mini-batch의 평균으로 구현한다.
(4) 뒤 식을 보면 L1 loss가 G에 대해서 추가적으로 달려있는 것을 볼 수 잇다.
해당 항은 G가 실제 gt값에 가까운 이미지를 형성하는데 도움을 주기 위해서 필요한 항이다.
논문에서는 random한 noise z에 대해서 언급하는데
z가 없다면 gan이 결정론적인 동일한 output만을 계속하여 만들어서 모델의 품질이 떨어지기에 필요하지만,
학습 과정에서 저절로 gan이 z를 무시하는 현상이 벌어져,
dropout을 통해 생성하는 결과물이 highly stochastic output을 낼 수 있도록 하려고 하였지만
그마저도 부족하여, 이에 대한 부분은 완전히 해결하지 못하였다고 한다.
추론 과정에서도 dropout을 사용하여, img2img 특성에 걸맞게 할 때마다 조금씩 다른 output이 생길 수 있음을 말한다.
2. u-net (G)

generator의 구조로써 U-net을 사용하였다고 한다.
일반 Encoder - decoder와 달리 U-net은 각 스케일마다 skip-connection을 사용하여 해상도별 정보를 보존한다.
(기존 encoder-decoder는 한번 bottleneck으로 압축되어 복원되기에 정보가 많이 손실된다. U-net은 skip connection으로 이러한 정보를 보내주는 것이다)
논문에서는 이를 bottleneck이 same underlying structure를 보존하고, skip connection이 surface appearance를 보존한다고 말한다.
3. PatchGAN (D)
기존의 L1/L2 Loss함수가 흐린 이미지를 생성해낸다는 것을 앞서 언급한바 있다.
이러한 L1/L2 Loss 를 통한 이미지 생성은 흐린 이미지를 생성해내지만, low frequency 를 충분히 잘 복원해낸다고 한다.
따라서 low frequency 영역은 L1/L2 loss로 충분하고 문제는 high frequency (선명함)을 보존하는 것인데,
이게 대해서 D가 high-frequency structure만 모델이 만들도록 제한하고, low frequency는 L1/L2가 보장하는 방식으로 선명함을 만들어낸다.
이때, 판별기는 N*N patch에 대해서 각 패치가 진짜인지 확인하는 방식으로 작동해 이를 PatchGan이라고 한다.
4. Optimization and inference
- 모델의 backward는 D에 대해서 한번 수행한뒤 , G에 대해서 수행하는 방식을 사용한다.
- G loss는 앞서 나온 loss의 뒤 항을 쓰는 게 아니라

를 사용한다. * fake를 진짜라고 믿게 만들어라
( 로그함수는 0에 가까우면 , -oo, 커지면 완만한 커브
초기 G가 생성해내는 값은 누가 봐도 가짜기에 log(1-D(fake))이면 D가 낮은 값을 밷어 log함수의 완만한 배에 올라타 gradient를 얻기 쉽지 않다.
반대로 log(D(fake)) 이면 초기에 비교적 완만하지 않아 gradient로 학습이 되는 것이다. )
- D의 objective를 1/2로 나누어서 G의 속도에 비해 D의 속도를 조절한다.
* 우리가 학습하는건 결국 G가 잘 만들도록 하는 것이고, 처음부터 가짜를 G는 만들어야 하기에 D를 느리게 하여 페이스를 조절한다!
4. Experiment
앞서 언급한 loss의 이유를 직관적으로 확인할 수 있다 + D의 high freq 보존

추가적으로 아래 fig를 보면 PatchGAN의 Patch size별 양상을 비교하는 것을 볼 수 있는데 너무 작으면 blur하너나 artifact가 생기고 너무 크면 부분적으로 이상한 것들을 생성해내는것을 확인할 수 있다.

마무리
이렇게 gan은 범용적인 img2img를 낮은 리소스로 수행할 수 있다.
입력 - gt 간의 관계를 학습하여 새로운 이미지에 대해서도 해당 관계를 가지는 이미지를 형성해 낼 수 있는 것이다.
최근에는 diffusion 계열이 이러한 img2img를 잘 하는 것으로 알고 있는데 후에 diffusion에 대한 review도 해보려고 합니다.
찾으며 diffusion poilcy라는 방법이 robotics에서도 핫하다는데 해당 방향성으로 공부를 조금 해 보려고 합니다.
직접 gan을 써보고 모델도 pix2pix는 아니지만 조금 더 복잡한걸로 구현해서 사용까지 해 봤는데 이러한 논문 정독 후 코드리뷰가 큰 도움이 됨을 느겼습니다.
그림 20000

'vision,deep learning' 카테고리의 다른 글
| [논문리뷰] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale - ViT (0) | 2026.01.12 |
|---|---|
| [논문리뷰]attention is all you need-2 (0) | 2026.01.05 |
| [논문리뷰]attention is all you need-1 (1) | 2025.12.29 |
| [논문리뷰]Attention is all you need-0 (0) | 2025.12.27 |