지난번 Attention is all you need 를 리뷰한 것에 이어 , vision에서 transformer가 성공적으로 적용된 모델인
ViT 논문에 대해서 리뷰해보겠습니다.
논문 arxiv link :
https://arxiv.org/abs/2010.11929
ABSTRACT
- Transformer가 자연어 처리 분야에서 성공을 겪은 것과 달리 computer vision 분야에서 이의 활용은 제한되어 왔다.
- 기존 vision 연구에서 attention은 CNN과 결합되어 사용되거나, CNN 전체 구조는 유지한체로 특정 요소를 대체하는 방식으로 활용되어 왔다.
- 위 논문에서는 CNN의 전체 구조 유지가 필요 없이, 이미지 patches들의 sequence에 대해 순수 transformer를 적용한 것이 이미지 분류에 있어서 잘 작동함을 보여주려 한다.
- 큰 사이즈의 dataset에 대해 pretrain하고, 기존 recognition benchmark들에 적용했을 때 이는 기존 CNN의 SOTA 성능에 맞먹는 성능을 보이면서, 학습에 있어서 더 적은 컴퓨팅 리소스를 필요로 했다.
INTRODUCTION
- Transforemer(Self-attention based architecture)는 NLP분야에서 거대 데이터에 대해 pre-train되고 , 작은 데이터셋에 대해 fine-tune하여 사용하는 방식으로 사용된다.
- Transforemer의 계산 효율성은 모델의 사이즈와 데이터셋이 커져도, 성능을 지속적으로 향상시키는데 도움을 준다.
- 이러한 자연어 분야에서 성공을 거둔 Transformer를 최대한 작은 수정을 통해 vision에 적용시키고자 한다.
이미지를 patch들로 쪼게고 해당 patch들의 선형 임베딩 seq이 transformer의 input으로 들어간다.
이미지 패치들은 NLP에서의 token(word)와 같이 다루어진다.
해당 방법을 ImageNet같은 midsize 데이터셋으로 학습시키면 , 모델의 성능은 Resnet에 못미치는 정도이다..
: Transformer가 CNN에 내제된 inductive bias ( translation equivariance , locality ) 를 가지지 못한다
-> 불충분한 데이터에서 Transformer는 잘 작동하지 않는다.
그러나, 충분히 큰 데이터셋으로 학습키면 학습이 inductive bias를 능가한다.
우리의 모델 Vit는 충분히 큰 데이터로 pre-train시키고 fewer datapoint 의 task로 transferred (fine-tune)했을 때 이전 SOTA 모델들의 벤치마크 성능을 압도했다.
* CNN의 inductive bias
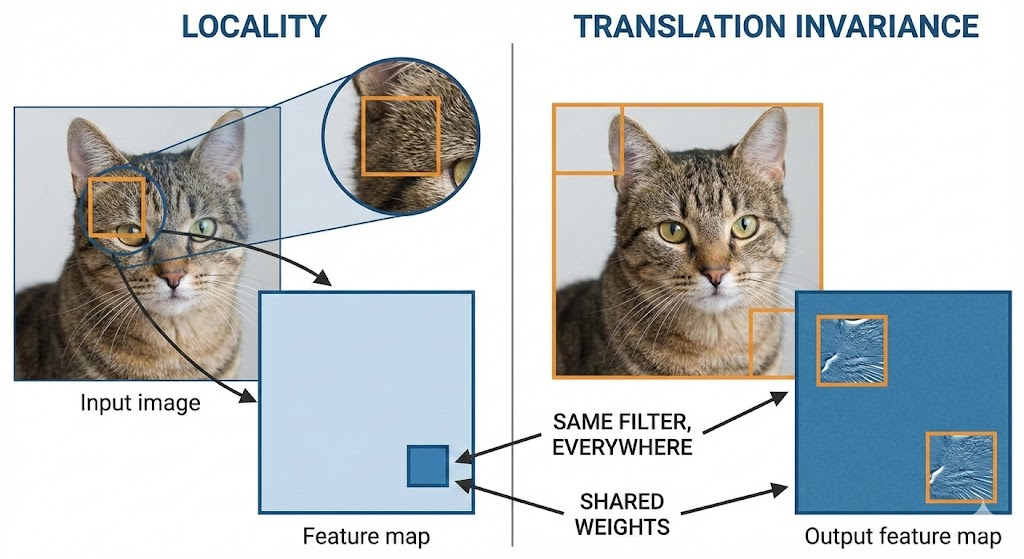
locality : output이 input의 국소적 이웃에 의존 - ( kernel로 인한 convolution 연산 의존 )
픽셀 간의 거리가 멀면 서로의 연관성이 낫다고 가정
Translation Invariace :
CNN은 동일한 kernel이 이미지 전체를 이동하며 계산
> 입력의 위치가 변하여도 불력 feature map의 활성화도 동일하게 변한다
입력의 위치가 변하여도, 출력 결과 (class)는 변하지 않음
METHOD


- patch embedding
1. H * W * C 차원의 입력을 가로세로 P인 패치 N개로 자른다 ... H*W*C > N*(P^2 * C)
2. transformer는 d사이즈의 벡터를 입력으로 사용 , D dimension로 trainable한 Linear projection E를 진행 (equ 1)
이러한 patch를 Linear projection 한 것을 patch embeddings 라고 한다.
- position embedding
patch의 position 정보를 넣기 위해 position embedding 을 추가함 (equ 1)
해당 논문에서는 2D position embedding에서 유의미산 성능 이점을 찾지 못했기에
최종적으로 stradard learnable 1D position embedding를 사용 , 이러한 position embedding은 encoder의 input으로 들어감
- CLS token
* BERT의 [class] token과 같은 맥락으로 학습 가능한 embedding 한개를 임베딩 시퀀스 앞에 추가 Xclass = z0
Transformer encoder를 통과한 뒤, 해당 토큰에 해당하는 z를 이미지 representation y로 사용한다.
pre-train과 fine-tunning에서 각각 classification head가 해당 토큰의 encoder 결과에 붙는다 (MLP가 붙는다는 말)
논문에서는 pre-train에서 1개의 hidden layer MLP를 , fine-tuning 에서는 1개의 linear layer를 사용한다.

- layer nomalization
transformer encoder는 MSA(multi head attention)과 MLP 블록으로 이루어져있다.
layer nomalization과 residual connection이 매 블록 후에 적용이 된다.
또한, MLP는 GELU로 비선형성을 가지며 2개의 layer를 가진다..
method - inductive bias
CNN에서는 locality - two dimensional neighborhood structure와 translation equivariance라는 구조적 가정이 들어가 있으며, 이러한 inductive bias가 전체 모델의 layer에 걸쳐 반영되어 있다.
그러나 Vit는 오직 MLP layer만이 이러한 inductive bias를 가지며 (self-attention은 global하게 적용됨)
two dimensional neighborhood structure는 모델의 시작 단계에서 이미지를 patch로 분할할떄와 ,
fine-tune할때 서로 다른 이미지의 해상도에 맞춰 position embedding을 조정할 떄에만 제한적으로 사용된다.
그러나 초기 시점의 position embedding은 2차원 정보를 아예 담고 있지 않으며 모든 공간적 관계는 처음부터 학습되어야 한다.
method - Hybrid Architecture
raw한 image를 patch의 input으로 넣는 것이 아닌 입력 seq를 CNN의 feature map을 input으로 구성하기도 한다.
CNN으로부터 얻어진 feature map에서 추출된 patch들을 대상으로 patch embedding projection을 진행한다 -
또한, 특별한 case로 patch의 spatial size를 1x1로 설정하여 가지게 시작하는 경우도 있다.
이 경우 입력 seq는 feature map의 단순히 펼친 뒤, 이를 Transforemr 차원으로 투영하는 방법으로 얻어진다.
method - FineTunning and higher resolution
보통 Vit는 큰 데이터셋에서 pre-train하고, 작은 데이터셋에서 fine-tunning하는 방법을 사용한다.
해당 과정에서 기존 prediction head는 제거하고 , 새로운 fine-tunning class 수에 맞는 초기화된 feedforward layer를 달아준다.
보통 fine - tunning에서는 pre-train보다 높은 해상도의 이미지를 쓰는 것이 좋은데,
이미지의 해상도가 높아지고 기존의 patch size는 같게 쓰는 것은 결과적으로 patch의 갯수가 많아짐 즉, seq의 길이가 길어짐을 의미한다.
이렇게 되면 기존의 pre-train 된 position vector가 무의미해지는 결과가 나오기에 , 사전학습된 position embedding을 2D 보간하는 방식으로 이전 pre-train에서의 position embedding의 효과를 다시 적용시킨다.
* 해당 해상도 조절과 patch extraction (2d 보간)이 vit에 inductive bias를 임의로 주입한 얼마 안되는 부분임을 주목 !
EXPERFIMENT
Vit 논문을 읽고 리뷰해보았습니다.
논문에서 언급된 CNN의 inductive bias와 관련하여 , vit가 large dataset에서 충분히 학습되어야 하는 이유를 인상깊게 읽었습니다.
추가로 모델 구조에서 사용된 , LN GELU에 대한 이해를 추가로 하고 모델코드를 분석하는 시간을 가지려고 합니다.
'vision,deep learning' 카테고리의 다른 글
| [논문리뷰] Image-to-Image Translation with Conditional Adversarial Networks (1) | 2026.02.14 |
|---|---|
| [논문리뷰]attention is all you need-2 (0) | 2026.01.05 |
| [논문리뷰]attention is all you need-1 (1) | 2025.12.29 |
| [논문리뷰]Attention is all you need-0 (0) | 2025.12.27 |