0. review gradient descent
저번 시간에 했던 gradient descent (경사하강법) 과 train 개념에 대해 복습한다.
- loss를 최소로 가지는 모델, True line(선형모델에서) 을 얻기 위해 loss를 최소로 가지는 w(가중치)를 구하는 것이 학습 train / learning 이다.
- train 과정 즉, 가중치 W를 loss가 적어지게 바꾸는 알고리즘 중 gradient descent (경사 하강법)을 배웟고 해당 알고리즘에서 기울기는 d_Loss / d_w로 정의한다.
$$
w = w - \alpha \cdot \frac{\partial \text{loss}}{\partial w}
$$
1. Back-propagation and Autograd
저번 시간까지는 선형 모델 (1차함수 형태)의 모델을 기준으로 경사하강법을 적용하여 train하는 것을 해 보았고, 이 과정에서 gradient는 직접 loss에 대한 식을 w에 대해 미분하여 직접manually하게 구하였다.
당연하게도 모델이 선형 모델만 있는 것도 아니고, 매우 복잡한 network를 가지고 있을 수 있다.
이런 경우 직접 loss에 대한 식을 구하고, 이를 w에 대해 미분하는 것은 고난이 될 수 있다.

Computation graph + chain rule
이에 대한 해결책으로 Computation graph 와 chain rule을 사용하여 구한다.
chain rule은 합성함수의 곱이라고 볼 수 있으며 이 의미는 input > output(input2) > final_output 과 같이 input과 output이 맞물려 있는 경우, 한개 함수의 output이 또 다른 함수의 input으로 들어가는 경우에 각각의 함수를 각각의 input변수에 대해 미분하고 곱하면 d_final_output / d_input 을 구할 수 있다는 것이다.
위의 fc_layer에서 여러 레이어가 맞물려 있는 경우 , 최종 Loss에 대해 처음 input layer의 가중치 w의 gradient를 구하려면 chain rule이 좋은 방법이 될 것을 상상해 볼 수 있다.
$$
\frac{dz}{dx} = \frac{dz}{dy} \cdot \frac{dy}{dx}
$$
Computation graph는 계산 과정을 노드와 엣지를 포함한 그래프로 표현한 것이다. 이렇게 말하면 와닫지 않을 수 있는데 디지털논리회로에서 논리 회로의 식을 AND ,NOR gate 등을 포함하여 그래프로 만드는 과정이 있는데 매우 유사하다는 생각을 했다.
단순 y= w*x라는 선형모델에 대해 loss를 계산하는 과정을 Computation graph로 그린 것을 아래에 첨부한다.
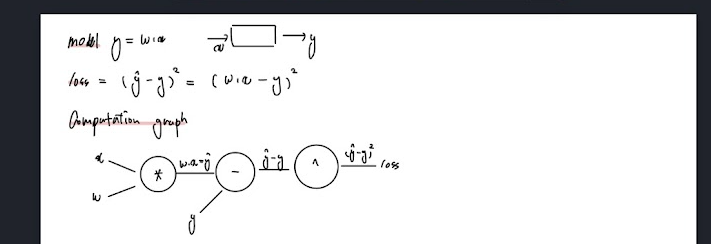
Computation graph + chain rule > Back-propagation
앞서 매운 computation graph와 chain rule을 활용하여 , foward pass 와 Back propagation 과정을 따라가보자.
다시 모델이 train되는 과정을 생각해보자.
1 epoch 첫 시작에서 w가중치는 random value로 배정되고, 주어진 정답dataset의 input 에 대해 설정된 w로 예측값 y_pred를 계산한다. 이후 dataset의 y value(label 정답값)과 y_pred의 거리 loss를 계산하게 된다. (foward pass)
이제 계산된 loss를 가지고, 가중치 w를 업데이트 해야 한다. 전 강의에서는 d_loss / d_w에 대한 식을 직접 구했지만 이번에는 그렇게 하지 않고 chain rule을 사용한다.
1. 각각의 gate에 대해 local gradient를 계산한다.
2. chain rule을 사용해, 마지막 gate의 local gradient 부터 최종까지 연결해 d_loss / d_w를 계산한다. (Back-propagation)
쉬운 과정인데 텍스트로 치는게 어려운 것 같다. 해당 chain rule로 돌아가면서 뒤의 가중치를 계산하고, 강의에서는 업데이트 하는 w가 하나였지만 가중치가 여러개고 겹겹히 쌓여있는 것을 chain rule로 계산하는 것을 생각해 보니 이게 역전파Back-propagation라고 불리는 것이 납득이 간다.
아래에 exercise 4-1 x = 2 , y = 4 , w =1 에 대한 foward pass 와 back - propagation 과정 풀이를 첨부한다.


2. Autograd with pytorch exercise
파이토치에서는 Computation graph를 구현하고 , gradient를 계산하는 과정이 자동화되어 있다. 강의에서는 torch 의 Variable을 사용해 Computation graph를 구현하는데 현 시점 tensor안에 해당 기능이 통합되었다. 따라서 강의와 코드가 다르고 , 의미도 어드정도 다르다.
https://tutorials.pytorch.kr/beginner/basics/intro.html 파이토치 한국어 듀토리얼
한줄한줄 기능을 살펴보자
1 - tensor, requires_grad = True
텐서를 선언
해당 텐서가 미분 대상인지 아닌지 보여주는 flag
[1.0],
텐서의 값 여기서는 random value인 1.0으로 시작 (1 * 1 크기 tensor인 것)
2 - .backward()
l 변수 (여기서는 loss 식)를 미분한다. 모든 변수에 대해 편미분 (역전파 과정), 여기서 Computation graph + chain rule > Back-propagation 과정을 한번에 해준다고 보면 된다.
3 - .grad
강의에서는 d_loss / d_w 의 값이 w. data에 저장된다고 알려줬지만 , gpt 피셜 최신 방법으로 grad를 더 추천한다고 한다.
각각 d_loss / dw 와 d_loss / db를 출력한다.
4. .torc.no_grad():
여기서 부터는 헷갈릴 수 잇다.
먼저 leaf tensor 에 대해 알아봐야 한다.
4.1 w-= rl * w.grad
leaf tensor란?
- 사람이 직접 만든 텐서고
- 계산의 결과물이 아니며
- 미분 가능한 대상
우리에게는 w가 leaf tensor라고 볼 수 있다.
a. torch는 leaf tensor에 대해 autograd를 저장한다.
즉 backward()를 호출하면,
Autograd는 계산 그래프를 따라 자동 미분을 수행하고,
그 결과는 "leaf tensor"의 .grad 속성에만 저장된다.
아래와 같은 방식(out of place)으로 식을 작성하면 torch는 w를 새로운 텐서로 형성하고
해당 w는 더 이상 leaf tensor가 아니게 된다.
따라서 아래와 같은 (in - place 식을 써야 한다. )
w -= rl * w.grad # l.grad = d_loss / d_w
4.2 with torch.no_grad()
torch 는 우리가 일반적인 수식을 코드로 작성하더라도 이를 모두 자동적으로 기억하고 그래프화 시킨다 Autograd. 여기서 그래프화 시킨다는 말은 모든 코드 수식에 대해 Computation graph을 그린다고 이해하면 된다.
나중에 .backward를 했을 때 자동 미분이 가능하게 이런 구현을 해놓은 것이다.
하지만 위 코드에서 경사하강법으로 w를 업데이트 하는 부분은 미분의 대상이 아니고, 계산 그래프에 포함되면 안 되는 연산 즉, autograd의 적용대상이 아니므로 그 부분을 예외처리하는 코드가
with torch.no_grad():
인 것이다.
4 - .grad.zero_()
torch에서는 grad값을 초기화 하지 않고, 다시 backward하면 기존 .grad에 단순합+= 누적되어 계산된다 이를 방지하기 위해
를 써준다.
전체 코드는 아래와 같다.
<+>
강의에서 사용한
와
를 사용하면
with torch.no_grad()와 in-place식을 사용하지 않고도, 동일하게 코드를 작성할 수 있다.
여기서 .data와 grad.data는 autograd 기능을 잠시 끄고, tensor의 raw data만을 가져오는 방법이다.
with torch.no_grad():
와 동일한 역할을 한다고 볼 수 잇다.
그러나 해당 방식은 .data로 직접 수정하는 경우 그래프가 손상될 위험이 커, 권장하지 않는다고 한다. .data를 사용한 코드는 아래와 같다. + gpt의 설명
🔹 .data 요약
- .data는 텐서의 실제 값만 추출한 버전으로, autograd(자동 미분) 추적에서 제외됩니다.
- 과거에는 gradient를 수동으로 수정할 때 .data를 사용했지만, 지금은 with torch.no_grad():가 더 안전하고 권장됩니다.
- .data를 잘못 사용하면 계산 그래프가 손상되어 학습이 제대로 되지 않을 수 있으므로, 특별한 경우가 아니면 사용을 피하는 것이 좋습니다.
🔧 .data가 왜 위험한가?
1. .data는 autograd 추적을 우회함
- .data로 접근한 텐서는 requires_grad=False 상태이며 autograd가 변화를 추적하지 않습니다.
- 이 상태에서 값을 변경하면, PyTorch는 변화가 있었다는 걸 감지하지 못합니다.
2. 계산 그래프는 여전히 연결되어 있다
- .data를 통해 수정한 텐서는 계산 그래프 상에서 부모 노드와 연결은 유지되지만, 수정된 값은 추적되지 않기 때문에 일관성이 깨집니다.
- 이로 인해 backward로 계산된 gradient가 잘못되거나, 오류는 없지만 학습이 엉망이 되는 경우가 발생합니다.
'vision,deep learning > PyTorchZeroToAll (in English) Review' 카테고리의 다른 글
| PyTorch Zero To All - 06 Logistic Regression Review (0) | 2025.05.14 |
|---|---|
| PyTorch Zero To All - 05 Linear Regression in the PyTorch way Review (1) | 2025.05.12 |
| PyTorch Zero To All - 03 Gradient Descent exercise (0) | 2025.05.09 |
| PyTorch Zero To All - 03 Gradient Descent Review (0) | 2025.05.08 |
| PyTorch Zero To All - 02 Linear Model Review (0) | 2025.05.08 |
